
在过去的十年中,人工智能(AI, artificial intelligence)已经在很大程度上渗透到我们的日常生活中。因此,我们对临床人工智能的期望非常高。然而,在医疗保健领域,特别是在围手术期医
在过去的十年中,人工智能(AI, artificial intelligence)已经在很大程度上渗透到我们的日常生活中。因此,我们对临床人工智能的期望非常高。然而,在医疗保健领域,特别是在围手术期医学领域,人工智能的影响仍然相对有限,这与其在数字科学领域的学术投资和生产力的指数式增长形成鲜明对比。在实施方面的挑战也有很多,包括技术和监管方面的挑战。此外,大规模部署临床人工智能的临床和经济影响仍然缺乏。然而,如果这些实施挑战得到妥善解决,人工智能在深刻改变我们实践的潜力方面是真实存在的。如果成功实施并整合到临床工作流程中,人工智能在辅助围手术期医学方面将变得更具预防性和个性化。然而,人工智能的实施并不是最后一步,它在实施后将面临新的挑战,包括算法维护、持续监测和改进。
在过去的几十年里,麻醉领域已经形成了医学界最强大的安全文化之一。在过去的几十年中,麻醉围手术期并发症的发生率大大降低,这正是促进危机防范和降低风险的价值所在。
尽管在减少术后短期并发症方面取得了突出的成就,但如果我们想让这种安全文化更上一层楼,麻醉医师仍然面临着巨大的挑战。我们需要将降低风险的策略扩展到手术室之外,以实现以病人为中心的长期术后结果。为了提高效率,我们还应该采取更多的预防措施。事实上,目前的风险缓解策略主要是基于危机防范的概念,凭借这一概念,我们能够准确地应对任何意想不到的危机。在这种模式下,我们的目标是做出反应,而实际上预防才是最终目的。风险缓解策略包括应用在人群层面上的方法和方案,但对个人层面上的影响和评估有限。推动围手术期护理的发展也在制定更加个性化的策略。
AI、机器学习(ML, machine learning)以及更普遍的预测分析方法在过去的十年研究中获得了很大的普及,这一点从研究出版物数量的激增中可以看出。简单的统计模型,如逻辑回归,可以被认为是机器学习的初级形式,已经在临床实践中用于风险分层。一个很好的例子是用于预测术后恶心和呕吐的apfel算法。尽管更先进的机器学习方法还没有实质性地渗透到临床领域,但它们在改变我们的实践和克服上述挑战方面的潜力是很重要的。为了更好地理解这种潜力,让我们看看ML和AI在我们专业领域的过去、现在和未来。
过去:麻醉学进入大数据和机器学习时代
古典与现代建模方法
几十年来,经典的统计方法已经被用于分析医疗数据,导致了风险分层评分的产生,例如阿普菲尔评分或手术后风险的阿普加评分。然而,在过去的十年中,值得注意的是,统计学家、计算机科学家、医生、数据科学家和更多的人已经转向ML,作为一种可行的解决方案来改进这些细化数据的分析。与传统的统计技术(如逻辑回归)相比,ML技术的优势并不明显。事实上,现代ML模型,有时被称为数据自适应模型,能更灵活地适应数据的复杂性,特别是变量之间复杂的相互作用。从这个意义上说,它们的适应性更强,可能更准确(虽然不一定正确),但也有更大的过拟合风险,即模拟噪声而不是真实的信号。
如果考虑到根据一组有限的输入变量(可能包括术中平均动脉血压、年龄、先前的心导管植入次数、手术中的失血量、起始血红蛋白等)来预先判断病人在麻醉后是否会出现心血管并发症的问题空间, 100%准确地预测哪些病人会在手术结束时发生术后心肌梗死(术后MI)是不可能的。目标是确定最接近 "最佳 "模型的统计模型来进行预测。传统的主项逻辑回归是用每个输入变量的线性和加法组合来模拟病人术后发生心血管并发症的可能性。因此,参数模型可以被描述为每个变量都有一个单一的旋钮的调谐板。模型将学习如何根据先前的分析案例和每个变量的值以及病人是否有术后心血管并发症来调整每个旋钮。在大多数情况下,这样的组合是对真正的底层数据生成机制的过度简化,导致预测性能不够理想。然而,好的一面是,这种(过度)简化的模型试图确定一个"连接点 "的一般和参数化的规则,并描述预测因素和所关注的结果之间的关系。例如,这个规则的最严格的形式可以是一条直线,例如普通最小平方模型所使用的直线。如果能找到这样的规则,它比更灵活的方法更不可能过度拟合数据。
更灵活的机器学习模型可以被描述为每个变量都有多个旋钮的调谐板,并同时影响多个变量。因此,这样的模型将允许每个变量输入之间有更复杂的相互作用,然后才是输出病人是否会出现术后并发症的可能性的最终方程式。在我们的例子中,这可能允许捕获这些输入变量之间的一些更复杂的生理相互作用,如血压、心率和容量状态之间的相互作用如何影响心肌的氧气供应和需求(图1)。

图1-参数模型与数据自适应模型对比
数据,或大或小,但质量要高
无论采用哪种建模方法,数据是统计引擎通用和必要的燃料。麻醉是一个领域,收集的数据中的细微差别为诊断和护理急性病人提供信息。在手术室和其他急性环境中,包括PACU以及医院和门诊中心的其他恢复单元,情况都是如此。从一个麻醉病例来看,如果收集详细的流程表数据,可能会有许多变量,每分钟都会存储数值,导致每个麻醉病例有数千到上万个数据点。一个机构每年要进行数万次麻醉,我们可以看到,数据量迅速增长,为从统计模式和关联中学习提供了巨大的机会。作为迈向AI准备的第一步,麻醉科必须进行数字化转型,并从纸质记录转向采用集成到医院电子病历的电子数据捕获平台。虽然实时数据采集和存储是关键,但整合到电子病历中可能同样重要,以便能够将围手术期发生的情况与医疗记录的其他部分联系起来,包括风险因素、治疗和结果。
虽然这种数字化转型已经发生,或者至少已经在许多医院开始实施,但用于研究目的的结构化数据的可用性仍然是一个重大挑战。MiMic是结构化数据收集和管理领域的先驱。该团队开发的模型(图2)已被许多其他团队采用,并很可能在未来几年内被用于麻醉领域。类似的例子已经存在于麻醉学中,尽管使用的模型略有不同。使用通用平台或方法进行数据收集、标记、整理和存储的好处是显而易见的。事实上,标准化数据的可用性将极大地简化模型的外部验证,从而有助于提高我们算法的通用性。此外,它将有助于在更多样化的数据上训练模型,从而在一定程度上降低算法偏差的风险。最后,这也将有助于在临床领域部署模型,在数据映射和预处理方面的先决条件更少。
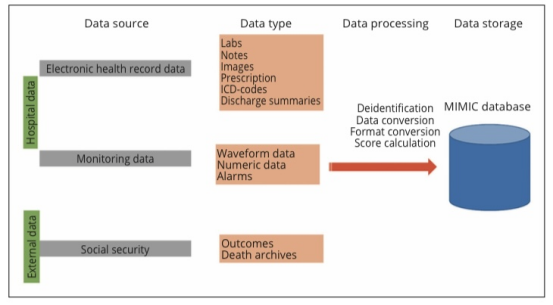
图2-MiMic的说明
麻醉的成功案例(以及一些不太成功的案例)
如前所述,安全文化、风险分层和降低扎根于麻醉实践中,这一事实可能解释了临床AI在这一医学领域能够率先部署和用于临床评估。2020年,Hashimoto等人发表了一篇系统综述,聚焦于人工智能在麻醉学中应用的六个主题:麻醉深度监测、麻醉控制、事件和风险预测、超声引导、疼痛管理和手术室后勤,并在1946年至2018年期间在同行评审期刊上发现了173项研究。在这些为麻醉和围术期护理而开发的众多AI算法中,有各种结果,包括术后住院死亡率、血流动力学不稳定、肺部并发症、急性肾衰竭、术后谵妄、术后慢性疼痛或阿片类药物使用等。
虽然这些算法大多是基于回顾性数据开发的,但值得一提的是,在医学领域,麻醉是为数不多的将临床人工智能推进到算法开发阶段的,有几项研究在算法最初开发后对其进行了前瞻性评估,甚至有研究使用前瞻性、随机、对照设计评估了在临床领域部署人工智能算法的好处。Schneck等人在一项小型试点单中心试验中评估了将HPI与方案指导的复苏策略一起使用的好处。他们发现,HPI算法与方案化治疗相结合,能够减少接受初级髋关节置换术的患者的低血压事件的发生率和持续时间。在HYPE试验中,作者测试了早期预警系统的临床应用与血流力学诊断指导和治疗协议相结合是否能够减少术中低血压。在这项非盲随机临床试验中,在全麻下计划进行选择性非心脏手术的成年患者中,患者随机分组接受早期预警系统(N.=34)或标准管理(N.=34),HPI的使用可减少术中低血压。同一小组对HYPE试验数据进行了事后分析,以检验术中HPI引导的血流动力学管理是否会减少PACU中术后低血压的严重程度。然而,他们发现术中HPI指导的血流动力学管理并没有降低术后低血压的发生率。另一项随机对照试验评估了使用HPI指导接受中等至高风险非心脏手术的患者术中血流动力学复苏的影响。这项针对214名患者的试点试验发现,指数指导并没有减少术中低血压的数量,而且大约一半的警报没有得到实际治疗。除了血流动力学不稳定和低血压预测外,最近还对其他采用AI算法的数字创新进行了评估,如复杂脊柱的AI引导针或闭环麻醉剂输送装置。
现在:人工智能在临床实践中的渗透有限
尽管我们的专业对包括人工智能在内的数字创新有明显的兴趣,但很明显,截至目前,人工智能在临床实践中的渗透仍然相对有限。在临床实践中实施和采用人工智能算法和临床决策支持工具的障碍有很多。正如Deo所说,"尽管有成千上万的论文将机器学习算法应用于医疗数据,但很少有对临床护理有贡献",而实施的障碍需要具体研究。这些障碍大多不局限于麻醉和围术期医学领域。世界卫生组织在题为《电子卫生的全球传播:实现全民健康》的报告中,就采用大数据的障碍对125个世卫组织成员国进行了调查。在这项调查中,72%的国家提到 "缺乏整合 "和 "隐私和安全"(68%)是采用大数据的非常或极其重要的障碍,约60%的国家还认为 "信息共享"、"推广标准 "和 "建设能力 "是重要障碍。55%的国家提到 "新的分析方法"。此外,据报告,在所有国家中,只有不到五分之一的国家制定了规范卫生部门大数据使用的国家政策或战略。基于这些结果,Wolff等人确定了三个改进类别:技术(数据碎片化和缺乏整合,医疗数据频繁噪声,不注重隐私的技术实施);政策(缺乏明确的专门监管机构、政策和标准);以及医疗和经济影响(缺乏医疗和经济影响措施)。He等人得出了类似的结论:"除了建立人工智能算法之外,将其'产品化'用于临床是非常复杂的"。图3总结了推进大规模部署的步骤。数据的可读性包括采用通用的标准化数据格式进行生成和存储,如观察性医疗结果合作伙伴关系(OMOP)通用数据模型(CDM),该模型使不同机构的信息(如编码器、患者、提供者、诊断、药物、测量和程序)以相同的格式采集。 数据共享也应在匿名化和脱敏化之后实现。正如He等人所说,"随着这种规模的传播,病人的保密性和隐私的概念可能需要完全重新考虑。"算法准备包括透明度和整合到临床工作流程中。透明度包括通过可变重要性的可解释性(即量化每个预测在最终预测中的相对权重)和不确定性量化(量化对每个预测的自信程度)。这两个方面对于评估对未被充分代表的子群体或少数群体的算法偏见的风险尤为重要。工作流程的整合需要与现有技术的互操作性,以及对终端用户的充分培训。系统准备包括建立具体的政策和监管标准来评估安全性和有效性。
它还意味着创建特定的质量控制实体,在部署后持续评估算法的性能,并可能在观察到性能的重大偏差时触发模型更新。开发者准备就绪意味着临床人工智能开发者必须准备好修改他们的价值主张,包括临床和财务影响的证据。考虑到这项任务的艰巨,一些人认为,参与人工智能的不同学术和临床人员应该重新组合,并建立一个共同的家园,例如,临床人工智能部门,以便他们开始更有凝聚力和更有效地合作。

图3-当前的障碍和潜在的解决方案
ML在麻醉、恢复室和PACU的应用前景
尽管在临床领域实施人工智能具有挑战性,但麻醉和围手术期医学一直对技术创新表现出极大的兴趣。如果成功地采用和整合,人工智能技术可能会在许多不同方面改变我们学科的未来。预计将发生两个根本性变化:1)从治疗到预防的方法的过渡;2)从一刀切的方法到个体化的方法。
预防医学
急性护理,包括围手术期和危重病人护理是治疗性医学的典型例子。事实上,病人来找我们时都有需要诊断和治疗的症状。相比之下,预防医学的目的是在危险的亚群体或个人发展到某种程度之前识别他们,并主动采取行动避免它。传统上,在治疗医学和预防医学之间有相对明确的区分。然而,人工智能和预测分析有可能打破这种分离。事实上,如果一个统计模型可以用来根据一系列预测因素(包括一些可操作的预测因素)准确地预测一个感兴趣的结果,那么下一步就是对一个可操作的预测因素进行虚拟干预,以获得反面的预测,即新的预测结果使病人经历了这个可操作的预测因素的不同值。为了更好地理解这一点,让我们考虑一下我们预测术中低血压的情况。在模型中,麻醉剂的剂量是低血压的一个可操作的预测因子。如果模型预测病人可能会出现低血压,我们可以要求模型预测如果麻醉剂的剂量减少20%,低血压的风险会是多少。预测结果和反事实预测结果之间的差异将告知临床医生如何最好地调整麻醉剂的使用,以最大限度地减少低血压的风险。这个超越预测分析的步骤通常被称为规范性分析。从治疗转向预防是一种根本性的转变,它有可能优化患者的预后,因为它可能有助于预防诸如低血压发作等不良后果的发生。
精准医疗
机器学习和人工智能也有可能提高我们提供个性化护理的能力。这场革命将由更大、更系统地获取数据来推动,包括电子病历数据、床边生成的高保真数据和以患者为中心的结果。数据的可用性和包容性越强,我们开发准确性、概括性、可迁移性和公正性的预测模型的能力就越强。虽然数据科学在过去几十年里一直专注于提高模型的准确性,但我们只触及了表面。然而,概括性、可迁移性和公正性至少与准确性同等重要。概括性是指在全部人口的样本上训练的算法在应用于全部目标人口时保持相似的性能。可迁移性是指算法应用于不同于原始样本的总体时的性能。算法公正性是一个关键而复杂的概念,它意味着算法性能在代表性不足的子组中不会降低,并且算法不会随着时间的推移而使无意识偏见长期存在。虽然前者可以通过确保训练数据反映整体人口并包括代表性不足的少数群体来解决,但后者非常复杂,因为它超出了数据的范围。新一代人工智能算法的发展也将促进基于个人的医学革命,这些算法可以在线方式学习,并从个体模式而不是从群体特征中学习。除了个性化预测,人工智能很快就会提供个性化预测和决策的可能性。基于人工智能根据对随机对照试验结果的解释,个性化治疗规则已被证明比二元规则(治疗所有人与不治疗任何人)提供了实质性的好处。
尽管临床人工智能的前景无疑一片光明,但未来也将带来新的挑战和风险。人工智能在临床实践中的成功实施需要工作流程的整合和对提供者的适当培训。在医学和护理学校的核心课程中整合数据科学是朝着这个方向迈出的重要的第一步。尽管有适当的培训和工作流程的整合,临床人工智能仍有可能改变患者-提供者和提供者-提供者关系的性质。医学信息学、电子健康记录和远程访问床边显示器的广泛使用已经影响了这种关系,更容易和更快的沟通,代价是更多的人与人之间的距离。然而,正如最近报道的那样,虽然有客观证据表明电子病历的使用可能会对医患沟通产生负面影响,但患者认为医患沟通没有受到影响,而且患者的满意度是稳定的。正如Hashimoto等人所强调的那样,临床AI的部署也会带来潜在的风险和伦理方面的问题。在已确定的风险中,我们可以列出算法错误和性能的渐进式漂移,缺乏可解释性,导致有限的采用或对预测的误解。最后,最近有人提出了严重的担忧,即算法对代表性不足的少数群体存在偏见,从而延续甚至增加医疗保健的不平等。这些风险和限制是成功实施的严重威胁。为了克服这些困难,需要在这些方面进行具体研究。
结论
尽管期望值很高,但人工智能在医疗领域,尤其是围手术期医学中的影响仍然相对有限。然而,如果目前的实施挑战得到妥善解决,人工智能深刻改变我们实践的潜力是真实存在的。如果成功实施并整合到临床工作流程中,人工智能辅助的围手术期医学可以在很大程度上实现预防性和个性化。然而,现实世界的实施将迅速发现新的挑战,包括算法的维护、持续监测和改进。人工智能转型仍处于起步阶段。









